The I/O system of Fortran is relatively powerful, flexible, and well-defined. Programs can be portable and device-independent even if they make extensive use of input/output facilities: this is difficult if not impossible in many other high-level languages. The effects of the hardware and operating system cannot, of course, be ignored entirely but they usually only affect fairly minor matters such as the forms of file-name and the maximum record length that can be used.
The READ and WRITE statements are most common and generally look like this:
READ(UNIT=*, FMT=*) NUMBER
WRITE(UNIT=13, ERR=999) NUMBER, ARRAY(1), ARRAY(N)
The pair of parentheses after the word READ or WRITE encloses
the control-list: a list of items which specifies where and how the
data transfer takes place. The items in this list are usually specified
with keywords. The list of data items to be read or written follow
the control-list.
Other input/output statements have a similar form except that they only have a control-list. There are the file-handling statements OPEN, CLOSE, and INQUIRE, as well as the REWIND and BACKSPACE statements which alter the currently active position within a file.
Before covering the these statements in detail, it is necessary to explain some of the concepts and terminology involved.
In Fortran the term file is used for anything that can be handled with a READ or WRITE statement: the term covers not just data files stored on disc or tape and also peripheral devices such as printers or terminals. Strictly these should all be called external files, to distinguish them from internal files.
An internal file is nothing more than a character variable or array which is used as a temporary file while the program is running. Internal files can be used with READ and WRITE statements in order to process character information under the control of a format specification. They cannot be used by other I/O statements.
Before an external file can be used it must be connected to an I/O unit. I/O units are integers which may be chosen freely from zero up to a system-dependent limit (usually at least 99). Except in OPEN and INQUIRE statements, files can only be referred to via their unit numbers.
The OPEN statement connects a named file to a numbered unit. It usually specifies whether the file already exists or whether a new one is to be created, for example:
OPEN(UNIT=1, FILE='B:INPUT.DAT', STATUS='OLD')
OPEN(UNIT=9, FILE='PRINTOUT', STATUS='NEW')
For simplicity most of the examples in this section show an actual
integer as the unit identifier, but it helps to make software more
modular and adaptable if a named constant or a variable is used
instead.
I/O units are a global resource. A file can be opened in any program unit; once it is open I/O operations can be performed on it in any program unit provided that the same unit number is used. The unit number can be held in an integer variable and passed to the procedure as an argument.
The connection between a file and a unit, once established, persists until:
Although all files are closed when the program exits, it is good practice to close them explicitly as soon as I/O operations on them are completed. If the program terminates abnormally, for example because an error occurs or it is aborted by the user, any files which are open, especially output files, may be left with incomplete or corrupted records.
The INQUIRE statement can be used to obtain information about the current properties of external files and I/O units. INQUIRE is particularly useful when writing library procedures which may have to run in a variety of different program environments. You can find out, for example, which unit numbers are free for use or whether a particular file exists and if so what its characteristics are.
A file consists of a sequence of records. In a text file a record corresponds to a line of text; in other cases a record has no physical basis, it is just a convenient collection of values chosen to suit the application. There is no need for a record to correspond to a disc sector or a tape block. READ and WRITE statements always start work at the beginning of a record and always transfer a whole number of records.
The rules of Fortran set no upper limit to the length of a record but, in practice, each operating system may do so. This may be different for different forms of record.
External files come in two varieties according to whether their records are formatted or unformatted. Formatted records store data in character-coded form, i.e. as lines of text. This makes them suitable for a wide range of applications since, depending on their contents, they may be legible to humans as well as computers. The main complication for the programmer is that each WRITE or READ statement must specify how each value is to be converted from internal to external form or vice-versa. This is usually done with a format specification.
Unformatted records store data in the internal code of the computer so that no format conversions are involved. This has a several advantages for files of numbers, especially floating-point numbers. Unformatted data transfers are simpler to program, faster in execution, and free from rounding errors. Furthermore the resulting data files, sometimes called binary files, are usually much smaller. A real number would, for example, have to be turned into a string of 10 or even 15 characters to preserve its precision on a formatted record, but on an unformatted record a real number typically occupies only 4 bytes i.e. the same as 4 characters. The drawback is that unformatted files are highly system-specific. They are usually illegible to humans and to other brands of computer and sometimes incompatible with files produced by other programming languages on the same machine. Unformatted files should only be used for information to be written and read by Fortran programs running on the same type of computer.
All peripheral devices allow files to be processed sequentially: you start at the beginning of the file and work through each record in turn. One important advantage of sequential files is that different records can have different lengths; the minimum record length is zero but the maximum is system-dependent.
Sequential files behave as if there were a pointer attached to the file which always indicates the next record to be transferred. On devices such as terminals and printers you can only read or write in strict sequential order, but when a file is stored on disc or tape it is possible to use the REWIND statement to reset this pointer to the start of the file, allowing it to be read in again or re-written. On suitable files the BACKSPACE statement can be used to move the pointer back by one record so that the last record can be read again or over-written.
One unfortunate omission from the Fortran Standard is that the position of the record pointer is not defined when an existing sequential file is opened. Most Fortran systems behave sensibly and make sure that they start at the beginning of the file, but there are a few rogue systems around which make it advisable, in portable software, to use REWIND after the OPEN statement. Another problem is how append new records to an existing sequential file. Some systems provide (as an extension) an ``append" option in the OPEN statement, but the best method using Standard Fortran is to open the file and read records one at a time until the end-of-file condition is encountered; then use BACKSPACE to move the pointer back and clear the end-of-file condition. New records can then be added in the usual way.
The alternative access method is direct-access which allows records to be read and written in any order. Most systems only permit this for files stored on random-access devices such as discs; it is sometimes also permitted on tapes. All records in a direct-access file must be the same length so that the system can compute the location of a record from its record number. The record length has to be chosen when the file is created and (on most systems) is then fixed for the life of the file. In Fortran, direct-access records are numbered from one upwards; each READ or WRITE statement specifies the record number at which the transfer starts.
Records may be written to a direct-access file in any order. Any record can be read provided that it exists, i.e. it has been written at some time since the file was created. Once a record has been written there is no way of deleting it, but its contents can be updated, i.e. replaced, at any time.
A few primitive operating systems require the maximum length of a direct-access file to be specified when the file is created; this is not necessary in systems which comply fully with the Fortran Standard.
Formatted and unformatted records cannot be mixed on the same file and on most systems files designed for sequential-access are quite distinct from those created for direct-access: thus there are four different types of external file. There is no special support in Standard Fortran for any other types of file such as indexed-sequential files or name-list files.
These are often just called text files. Terminals and printers should
always be treated as formatted sequential files. Data files of this type
can be created in a variety of ways, for example by direct entry from the
keyboard, or by using a text editor. Some Fortran systems do not allow
records to be longer than a normal line of text, for example 132
characters. Unless a text file is pre-connected it must be opened with
an OPEN statement, but the FORM= and ACCESS= keywords
are not needed as the default values are suitable:
OPEN(UNIT=4, FILE='REPORT', STATUS='NEW')
All data transfers must be carried out under format control. There
are two options with files of this type: you can either provide your
own format specification or use list-directed formatting.
The attraction of list-directed I/O is that the Fortran system does the work, providing simple data transfers with little programming effort. They are specified by having an asterisk as the format identifier:
WRITE(UNIT=*, FMT=*)'Enter velocity: '
READ(UNIT=*, FMT=*, END=999) SPEED
List-directed input is quite convenient when reading numbers from
a terminal since it allows virtually ``free-format" data entry. It may
also be useful when reading data files where the layout is not
regular enough to be handled by a format specification. List-directed output is satisfactory when used just to output a character
string (as in the example above), but it produces less pleasing
results when used to output numerical values since you have no
control over the positioning of items on the line, the field-width,
or the number of decimal digits displayed. Thus:
WRITE(UNIT=LP, FMT=*)' Box of',N,' costs �',PRICE
will produce a record something like this: Box of 12 costs � 9.5000000The alternative is to provide a format specification: this provides complete control over the data transfer. The previous example can be modified to use a format specification like this:
WRITE(UNIT=LP, FMT=55)'Box of',N,' costs �',PRICE
55 FORMAT(1X, A, I3, A, F6.2)
and will produce a record like this: Box of 12 costs � 9.50One unusual feature of input under control of a format specification is that each line of text will appear to be padded out on the right with an indefinite number of blanks irrespective of the actual length of the data record. This means that, among other things, it is not possible to distinguish between an empty record and one filled with blanks. If numbers are read from an empty record they will simply be zero.
Unformatted sequential files are often used as to transfer data from one program to another. They are also suitable for scratch files, i.e. those used temporarily during program execution. The only limit on the length of unformatted records is that set by the operating system; most systems allow records to contain a few thousand data items at least. The OPEN statement must specify the file format, but the default access method is ``sequential". Each READ or WRITE statement transfers one unformatted record.
For example, these statements open an existing unformatted file and read two records from it:
OPEN(UNIT=15, FILE='BIN', STATUS='OLD', FORM='UNFORMATTED')
READ(15) HEIGHT, LENGTH, WIDTH
READ(15) ARRAYP, ARRAYQ
BACKSPACE and REWIND statements may generally be used on
all unformatted sequential files.
Since direct-access files are readable only by machine, it seems sensible to use unformatted records to maximise efficiency. The OPEN statement must specify ACCESS='DIRECT' and also specify the record length. Unfortunately the units used to measure the length of a record are not standardised: some systems measure them in bytes, others in numerical storage units, i.e. the number of real or integer variables a record can hold (see section 5.1). This is a minor obstacle to portability and means that you may need to know how many bytes your machine uses for each numerical storage unit, although this is just about the only place in Fortran where this is necessary. Most systems will allow you to open an existing file only if the record length is the same as that used when the file was created.
Each READ and WRITE statement transfers exactly one record and must specify the number of that record: an integer value from one upwards. The record length must not be greater than that declared in the OPEN statement; if an output record is not completely filled the remainder is undefined.
To illustrate how direct-access files can be used, here is a complete program which allows a very simple data-base, such as a set of stock records, to be examined. Assuming that the record length is measured in numerical storage units of 4 bytes, the required record length in this case can be computed as follows:
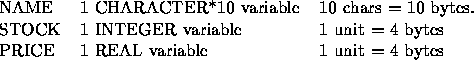
The total record length is 18 bytes or 5 numerical storage units (rounding up to the next integer).
PROGRAM DBASE1
INTEGER STOCK, NERR
REAL PRICE
CHARACTER NAME*10
*Assume record length in storage units holding 4 chars each.
OPEN(UNIT=1, FILE='STOCKS', STATUS='OLD',
$ ACCESS='DIRECT', RECL=5)
100 CONTINUE
*Ask user for part number which will be used as record number.
WRITE(UNIT=*,FMT=*)'Enter part number (or zero to quit):'
READ(UNIT=*,FMT=*) NPART
IF(NPART .LE. 0) STOP
READ(UNIT=1, REC=NPART, IOSTAT=NERR) NAME, STOCK, PRICE
IF(NERR .NE. 0) THEN
WRITE(UNIT=*,FMT=*)'Unknown part number, re-enter'
GO TO 100
END IF
WRITE(*,115)STOCK, NAME, PRICE
115 FORMAT(1X,'Stock is',I4, 1X, A,' at �', F8.2, ' each')
GO TO 100
END
The typical output record of the program will be of the form: Stock is 123 widgets at � 556.89 each
Formatted direct-access files are slightly more portable than the unformatted form because their record length is always measured in characters. Otherwise there is little to be said for them. The OPEN statement must specify both ACCESS='DIRECT' and FORM='FORMATTED' and each READ and WRITE statement must contain both format and record-number identifiers. List-directed transfers are not permitted. If the format specification requires more than one record to be used, these additional records follow on sequentially from that specified by REC=. It is an error to try to read beyond the end of a record, but an incompletely filled record will be padded out with blanks.
An internal file is an area of central memory which can be used as if it were a formatted sequential file. It exists, of course, only while the program is executing. Internal files are used for a variety of purposes, particularly to carry out data conversions to and from character data type. Some earlier versions of Fortran included ENCODE and DECODE statements: the internal file READ (which replaces DECODE) and internal file WRITE (which replaces ENCODE) are simpler, more flexible, and entirely portable.
An internal file can only be used with READ and WRITE statements and an explicit format specification is required: list-directed transfers are not permitted. The unit must have character data type but it can be a variable, array element, substring, or a complete array. If it is a complete array then each array element constitutes a record; in all other cases the file only consists of one record. Data transfers always start at the beginning of the internal file, that is an implicit rewind is performed each time. The record length is the length of the character item. It is illegal to try to transfer more characters than the internal file contains, but if a record of too few characters is written it will be padded out with blanks. The END= and IOSTAT= mechanisms can be used to detect the end-of-file.
An internal file WRITE is typically used to convert a numerical value to a character string by using a suitable format specification, for example:
CHARACTER*8 CVAL
RVALUE = 98.6
WRITE(CVAL, '(SP, F7.2)') RVALUE
The WRITE statement will fill the character variable CVAL with
the characters ' +98.60 ' (note that there is one blank at each end
of
the number, the first because the number is right-justified in the
field of 7 characters, the second because the record is padded out
to the declared length of 8 characters).
Once a number has been turned into a character-string it can be processed further in the various ways described in section 7. This makes it possible, for example, to write numbers left-justified in a field, or mark negative numbers with with ``DR" (as in bank statements) in or even use a pair of parentheses (as in balance-sheets). With suitable arithmetic you can even output values in other number-bases such as octal or hexadecimal. Even more elaborate conversions may be achieved by first writing a suitable format specification into a character string and then using that format to carry out the desired conversion.
Internal file READ statements can be used to decode a character string containing a numerical value. One obvious application is to handle the user input to a command-driven program. Suppose the command line consists of a word followed, optionally, by a number (in integer or real format), with at least one blank separating the two. Thus the input commands might be something like:
UP 4 RIGHT 123.45A simple way to deal with this is to read the whole line into a character variable and then use the INDEX function to locate the first blank. The preceding characters constitute the command word, those following can be converted to a real number using an internal file READ. For example:
CHARACTER CLINE*80
* . . .
100 WRITE(UNIT=*,FMT=*)'Enter command: '
READ(*, '(A)', IOSTAT=KODE) CLINE
IF(KODE .NE. 0) STOP
K = INDEX(CLINE, ' ')
*The command word is now in CLINE(1:K-1); Assume the
* number is in the next 20 characters: read it into RVALUE
READ(CLINE(K+1:), '(BN,F20.0)', IOSTAT=KODE)
RVALUE
IF(KODE .NE. 0) THEN
WRITE(UNIT=*,FMT=*)'Error in number: try again'
GO TO 100
END IF
Note that the edit descriptor BN is needed to ensure that any
trailing blanks will be ignored; the F20.0 will then handle any real
or integer constant anywhere in the next 20 characters. A field of
blanks will be converted into zero.
Many programs are interactive and need to access the user's terminal. Although the terminal is a file which can be connected with an OPEN statement, its name is system-dependent. Fortran solves the problem by providing two special files usually called the standard input file and the standard output file. These files are pre-connected, i.e. no OPEN statement is needed (or permitted). They are both formatted sequential files and, on interactive systems, handle input and output to the terminal. You can READ and WRITE from these files simply by having an asterisk ``*" as the unit identifier. These files make terminal I/O simple and portable; examples of their use can be found throughout this book.
When a program is run in batch mode most systems arrange for standard output to be diverted to a log file or to the system printer. There may be some similar arrangement for the standard input file.
The asterisk notation has one slight drawback: the unit numbers is often specified by an integer variable so that the source of input or destination of output can be switched from one file to another merely be altering the value of this integer. This cannot be done with the standard input or output files.
In order to retain compatibility with Fortran66, many systems provide other pre-connected files. It used to be customary to have unit 5 connected to the card-reader, and unit 6 to the line printer. Other units were usually connected to disc files with appropriate names: thus unit 39 might be connected to a file called FTN039.DAT or even TAPE39. These pre-connections are completely obsolete and should be ignored: an OPEN statement can supersede a pre-connection on any numbered unit. Unfortunately these obsolete pre-connections can have unexpected side effects. If you forget to open an output file you may find that your program will run without error but that the results will be hidden on a file with one of these special names.
Errors in most executable statements can be prevented by taking sufficient care in writing the program, but in I/O statements errors can be caused by events beyond the control of the programmer: for example through trying to open a file which no longer exists, writing to a disc which is full, or reading a data file which has been created with the wrong format. Since I/O statements are so vulnerable, Fortran provides an error-handling mechanism for them. There are actually two different ways of handling errors which may be used independently or in combination.
Firstly, you can include in the I/O control list an item of the form:
IOSTAT=integer-variable
When the statement has executed the integer variable (or array
element) will be assigned a value representing the I/O status. If the
statement has completed successfully this variable is set to zero,
otherwise it is set to some other value, a positive number if an
error has occurred, or a negative value if the end of an input file
was detected. Since the value of this status code is system-dependent, in portable software the most you can do is to compare
it to zero and, possibly, report the actual error code to the user.
Thus:
100 WRITE(UNIT=*, FMT=*)'Enter name of input file: '
READ(UNIT=*, FMT=*) FNAME
OPEN(UNIT=INPUT, FILE=FNAME, STATUS='OLD', IOSTAT=KODE)
IF(KODE .NE. 0) THEN
WRITE(UNIT=*,FMT=*)FNAME, ' cannot be opened'
GO TO 100
END IF
This simple error-handling scheme makes the program just a little
more user-friendly: if the file cannot be opened, perhaps because
it does not exist, the program asks for another file-name.
The second method is to include an item of the form
ERR=label
which causes control to be transferred to the statement attached to
that label in the event of an error. This must, of course, be an
executable statement and in the same program unit. For example:
READ(UNIT=IN, FMT=*, ERR=999) VOLTS, AMPS
WATTS = VOLTS * AMPS
* rest of program in here . . . . . and finally
STOP
999 WRITE(UNIT=*,FMT=*)'Error reading VOLTS or AMPS'
END
This method has its uses but is open to the same objections as the
GO TO statement: it often leads to badly-structured programs with
lots of arbitrary jumps.
By using both IOSTAT= and ERR= in the same statement it is possible to find out the actual error number and jump to the error-handling code. The presence of either keyword in an I/O statement will allow the program to continue after an I/O error; on most systems it also prevents an error message being issued.
The ERR= and IOSTAT= items can be used in all I/O statements. Professional programmers should make extensive use of these error-handling mechanisms to enhance the robustness and user-friendliness of their software.
There is one fairly common mistake which does not count as an errors for this purpose: if you write a number to a formatted record using a field width too narrow to contain it, the field will simply be filled with asterisks.
If an error occurs in a data transfer statement then the position of the file becomes indeterminate. It may be quite difficult to locate the offending record if an error is detected when transferring a large array or using a large number of records.
A READ statement which tries to read a record beyond the end of a sequential or internal file will trigger the end-of-file condition. If an item of the form: IOSTAT=integer-variable is included in its control-list then the status value will be returned as some negative number. If it includes an item of the form: END=label then control is transferred to the labelled statement when the end-of-file condition is detected.
The END= keyword may only be used in READ statements, but it is can be used in the presence of both ERR= and IOSTAT= keywords. End-of-file detection is very useful when reading a file of unknown length, but some caution is necessary. If you read several records at a time from a formatted file there is no easy way of knowing exactly where the end-of-file condition occurred. The data list items beyond that point will have their values unaltered. Note also that there is no concept of end-of-file on direct-access files: it is simply an error to read a record which does not exist, whether it is beyond the ``end" of the file or not.
Most systems provide some method for signalling end-of-file on terminal input: those based on the ASCII code often use the character ETX which is usually produced by pressing control/Z on the keyboard (or EOT which is control/D). After an end-of-file condition has been raised in this way it may persist, preventing further terminal input to that program.
Formally, the Fortran Standard only requires Fortran systems to detect the end-of-file condition on external files if there is a special ``end-file" record on the end. The END FILE statement is provided specifically to write such a record. In practice, however, virtually all Fortran systems respond perfectly well when you try to read the first non-existent record, so that the END FILE statement is effectively obsolete and is not recommended for general use.
Every READ or WRITE statement which uses a formatted external file or an internal file must include a format identifier. This may have any of the following forms:
A format specification consists a pair of parentheses enclosing a list of items called edit descriptors. Any blanks before the left parenthesis will be ignored and (except in a FORMAT statement) all characters after the matching right parenthesis are ignored.
In most cases the format can be chosen when the program is
written and the simplest option is to use a character constant:
WRITE(UNIT=LP, FMT='(1X,A,F10.5)') 'Frequency =', HERTZ
Alternatively you can use a FORMAT statement:
WRITE(UNIT=LP, FMT=915) 'Frequency =', HERTZ
915 FORMAT(1X, A, F10.5)
This allows the same format to be used by more than one data-transfer
statement. The FORMAT statement may also be the neater form if the
specification is long and complicated, or if character-constant
descriptors are involved, since the enclosing apostrophes have to be
doubled up if the whole format is part of another character constant.
It is also possible to compute a format specification at run-time by using a suitable character expression. By this means you could, for example, arrange to read the format specification of a data file from the first record of the file. The program fragment below shows how to output a real number in fixed-point format (F10.2) when it is small, changing to exponential format (E18.6) when it is larger. A threshold of a million has been chosen here.
CHARACTER F1*(*), F2*12, F3*(*)
*Items F1, F2, F3 hold the three parts of a format specification.
*F1 and F3 are constants, F2 is a variable.
PARAMETER (F1 = '(1X,''Peak size ='',')
PARAMETER (F3 = ')')
*... calculation of PEAK assumed to be in here
IF(PEAK .LT. 1.0E6) THEN
F2 = 'F10.2'
ELSE
F2 = 'E18.6'
END IF
WRITE(UNIT=*, FMT=F1//F2//F3) PEAK
Note that the apostrophes surrounding the character constant 'Peak
size =' have been doubled in the PARAMETER statement because
they are inside another character constant. Here are two examples
of output records, with blanks shown explicitly:
Peak size = 12345.67 Peak size = 0.987654E+08
The FORMAT statement is classed as non-executable and can, in principle, go almost anywhere in the program unit. A FORMAT statement can, of course, be continued so its maximum length is 20 lines. The same FORMAT statement can be used by more than one data transfer statement and, unless it contains character constant descriptors, used for both input and output. Since it is very easy to make a mistake in matching the items in a data transfer list with the edit descriptors in the format specification, it makes sense to put the FORMAT statement as close as possible to the READ and WRITE statements which use it.
There are two types of edit descriptor: data descriptors and control descriptors.
A data descriptor must be provided for each data item transferred by a READ or WRITE statement; the descriptors permitted depend on the data type of the item. The data descriptors all start with a letter indicating the data type followed by an unsigned integer denoting the field width, for example: I5 denotes an integer field 5 characters wide, F9.2 denotes a floating-point field 9 character wide with 2 digits after the decimal point. Full details of all the data descriptors are given in the next section.
The control descriptors are used for a variety of purposes, such as tabbing to specific columns, producing or skipping records, and controlling the transfer of subsequent numerical data. They are described fully in section 10.9.
Note that only literal constants are permitted within format specifications, not named constants or variables.
A data descriptor must be provided for each data item present (or implied) in a data transfer list. Real, double precision, and complex items may use any of the E, F, or G descriptors but in all other cases the data type must match. Two floating-point descriptors are needed for each complex value.

The letters w, m, d, and e used with these data descriptors represent unsigned integer constants; w and e must be greater than zero.

Any data descriptor can be preceded by a repeat-count (also an
unsigned integer), thus:
3F6.0 is equivalent to { F6.0,F6.0,F6.0
This facility is particularly useful when handling arrays.
Numbers are always converted using the decimal number base: there is no provision in Standard Fortran for transfers in other number bases such as octal or hexadecimal. More complicated conversions such as these can be performed with the aid of internal files.
On output number are generally right-justified in the specified field; leading blanks are supplied where necessary. Negative values are always preceded by a minus sign (for which space must be allowed in the field); zero is always unsigned; the SP and SS descriptors control whether positive numbers are to be preceded by a plus sign or not. A number which is too large to fit into its field will appear instead as a set of w asterisks.
On input numbers should be right-justified in each field. All forms of constant permitted in a Fortran program can safely be used in an input field of the corresponding type, as long there are no embedded or trailing blanks. Leading blanks are always ignored; a field which is entirely blank will be read as zero. The treatment of embedded and trailing blanks can be controlled with the BN and BZ descriptors. The rules here are another relic of very early Fortran systems.
When reading a file which has been connected by means of an OPEN statement (provided it does not contain BLANK='ZERO') all embedded and trailing blanks in numeric input fields are treated as nulls, i.e. they are ignored. In all other cases, such as input from the standard pre-connected file or from an internal file, embedded and trailing blanks are treated as zeros. These defaults can be altered with the BN and BZ control descriptors. It is hard to imagine any circumstances in which it is desirable to interpret embedded blanks as zeros; the default settings are particularly ill-chosen since numbers entered by a user at a terminal are often left-justified and may appear to be padded out with zeros. Errors from this source can be avoided by using BN at the beginning of all input format specifications.
An integer value written with Iw appears right-justified in a field of w characters with leading blanks. Iw.m is similar but ensures that at least m digits will appear even if leading zeros are necessary. This is useful, for instance, to output the times in hours and minutes:
NHOURS = 8
MINUTE = 6
WRITE(UNIT=*, FMT='(I4.2, I2.2)') NHOURS, MINUTE
The output record (with blanks shown explicitly) is:
0806On input Iw and Iw.m are identical. Note that an integer field must not contain a decimal point, exponent, or any punctuation characters such as commas.
Data of any of the floating-point types (Real, Double Precision, and Complex) may be transferred using any of the descriptors E, F, or G. For each complex number two descriptors must be provided, one for each component; these components may be separated, if required, by control descriptors. On output numbers are rounded to the specified number of digits. All floating-point data transfers are affected by the setting of the scale-factor; this is initially zero but can be altered by the P control descriptor, as explained in the section 10.9.
Output using Fw.d produces a fixed-point value in a field of w characters with exactly d digits after the decimal point. The decimal point is present even if w is zero, so that if a sign is produced there is only space for, at most, w-2 digits before the decimal point. If it is really important to suppress the decimal point in numbers with no fractional part one way is to use a format specification of the form (F15.0,TL1)... so that the next field starts one place to the left and over-writes the decimal point. Another way is to copy the number to an integer variable and write it with an I descriptor, but note the limited range of integers on most systems. F format is especially convenient in tabular layouts since the decimal points will line up in successive records, but it is not suitable for very large or small numbers.
Output with Ew.d produces a number in exponential or ``scientific" notation. The mantissa will be between 0.1 and 1 (if the scale-factor is zero). The form Ew.dEe specifies that there should be exactly e digits in the exponent. This form must be used if the exponent will have more than three digits (although this problem does not arise on machines on which the number range is too small). E format can be used to handle numbers of any magnitude. The disadvantage is that exceptionally large or small values do not stand out very well in the resulting columns of figures.
Gw.d is the general-purpose descriptor: if the value is greater than 0.1 but not too large to fit it the field it will be written using a fixed-point format with d digits in total and with 4 blanks at the end of the field; otherwise it is equivalent to Ew.d format. The form Gw.dEe allows you to specify the length of the exponent; if a fixed-point format is chosen there are e+2 blanks at the end.
The next example shows the different properties of these three formats on output:
X = 123.456789
Y = 0.09876543
WRITE(UNIT=*, FMT='(E12.5, F12.5, G12.5)') X,X,X, Y,Y,Y
produces two records (with 0.12346E+03 123.45679 123.46 0.98766E-01 0.09877 0.98766E-01On input all the E, F, and G descriptors have identical effects: if the input field contains an explicit decimal point it always takes precedence, otherwise the last d digits are taken as the decimal fraction. If an exponent is used it may be preceded by E or D (but the exponent letter is optional if the exponent is signed). If the input field provides more digits than the internal storage can utilise, the extra precision is ignored. It is usually best to use ( Fw.0) which will cope with all common floating-point or even integer forms.
When a logical value is written with Lw the field will contain the letter T or F preceded by (w-1) blanks. On input the field must contain the letter T or F; the letter may be preceded by a decimal point and any number of blanks. Characters after the T or F are ignored. Thus the forms .TRUE. and .FALSE. are acceptable.
If the A descriptor is used without an explicit field-width then the length of the character item in the data-transfer list determines it. This is generally what is required but note that the position of the remaining items in the record will change if the length of the character item is altered.
If is important to use fixed column layouts the form Aw may be preferred: it always uses a field w characters wide. On output if the actual length len is less than w the value is right-justified in the field and preceded by (w-len) blanks; otherwise only the first w characters are output, the rest are ignored. On input if the length len is less than w then the right-most len characters are used, otherwise w characters will be read into the character variable with (len-w) blanks appended.
Control descriptors do not correspond to any item in the data-transfer list: they are obeyed when the format scan reaches that point in the list. A format specification consisting of nothing but control descriptors is valid only if the READ or WRITE statement has an empty data-transfer list.
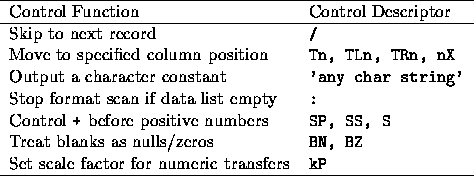
Here n and k are integer constants, k may have a sign but n must be non-zero and unsigned. The control descriptors such as SP, BN, kP affect all numbers transferred subsequently. The settings are unaffected by forced reversion but the system defaults are restored at the start of the next READ or WRITE operation.
Any list of edit descriptors may be enclosed in parentheses and
preceded by an integer constant as a repetition count, e.g.
2(I2.2, '-'),I2.2
is equivalent to
I2.2, '-', I2.2, '-', I2.2
These sub-lists can be nested to any reasonable depth, but the
presence of internal pairs of parentheses can have special effects
when forced reversion takes place, as explained later.
Commas may be omitted between items in the following special cases: either side of a slash (/) or colon (:) descriptor, and after a scale-factor (kP) if it immediately precedes a D, E, F, or G descriptor.
The slash descriptor (/) starts a new record on output or skips to a new record on input, ignoring anything left on the current record. On a text file a record normally corresponds to a line of text. Note that a formatted transfer always process at least one record: if the format contains N slashes then a total of (N+1) records are processed. With N consecutive slashes in an output format there will be (N-1) blank lines; on input then (N-1) lines will be ignored. Note that if a formatted sequential file is sent to a printer the first character of every record may be used for carriage-control (see section 10.11). It is good practice to put 1X at the beginning of every format specification and after every slash to ensure single line spacing. Here, for example, there is a blank line after the column headings.
WRITE(UNIT=LP, FMT=95) (NYEAR(I), POP(I), I=1,NYEARS)
95 FORMAT(1X,'Year Population', //, 100(1X, I4, F12.0, /))
These descriptors cause subsequent values to be transferred starting at a different column position in the record. They can, for instance, be used to set up a table with headings positioned over each column. In all these descriptors the value of n must be 1 or more. Columns are numbered from 1 on the left (but remember that column 1 may be used for carriage-control if the output is sent to a printer).

On input TLn can be used to re-read the same field again, possibly using a different data descriptor. On output these descriptors do not necessarily have any direct effect on the record: they do not cause any existing characters to be replaced by blanks, but when the record is complete any column positions embedded in the record which are still unset will be replaced by blanks. Thus:
WRITE(UNIT=LP, FMT=9000)
9000 FORMAT('A', TR1000, TL950, 'Z')
will cause a record of 52 characters to be output, middle 50 of
them blanks.
The character constant descriptor can only be used with WRITE statements: the character string is simply copied to the output record. As in all character constants an apostrophe can be represented in the string by two successive apostrophes, and blanks are significant.
After SP has been used, positive numbers will be written with a leading + sign; after SS has been used the + sign is suppressed. The S descriptor restores the initial default which is system-dependent. These descriptors have no effect on numerical input. The initial default is restored at the start of every new formatted transfer.
After BN is used all embedded and trailing blanks in numerical input fields are treated as nulls, i.e. ignored. After BZ they are treated as zeros. These descriptors have no effect on numerical output. The initial default, which depends on the BLANK= item in the OPEN statement, is restored at the start of every new formatted transfer.
The scale factor can be used to introduce a scaling by any power of 10 between internal and external values when E, F, or G descriptors are used. In principle this could be useful when dealing with data which are too large, or too small, for the exponent range of the floating-point data types of the machine, but in other difficulties usually make this impracticable. The scale factor can result in particularly insidious errors when used with F descriptors and should be avoided by all sensible programmers. The rules are as follows.
The initial scale factor in each formatted transfer is zero. It the
descriptor kP is used, where k is a small (optionally signed)
integer, then it is set to k. It affects all subsequent floating
point
values transferred by the statement. On input there is no effect if
the input field contains an explicit exponent, otherwise
On output the effect depends on the descriptor used. With E
descriptors the decimal point is moved k places to the right and
the exponent reduced by k so the effective value is unaltered.
With F descriptors there is always a scaling:
With G descriptors the scale-factor is ignored if the value is in
the
range for F-type output, otherwise it has the same effects as with
E descriptors.
The list of edit descriptors is scanned from left to right (apart from the effect of parentheses) starting at the beginning of the list whenever a new data transfer statement is executed. The action of the I/O system depends jointly on the next edit descriptor and the next item in data-transfer list. If a data descriptor comes next then the next data item is transferred if one exists, otherwise the format scan comes to an end. If a colon descriptor (:) comes next and the data-transfer list is empty the format scan ends, otherwise the descriptor has no effect. If any other control descriptor comes next then it is obeyed whether or not the data-transfer list is empty.
If the format list is exhausted when there are still more items in the data-transfer list then forced reversion occurs: the file is positioned at the beginning of the next record and the format list is scanned again, starting at the left-parenthesis matching the last preceding right-parenthesis. If this is preceded by a repeat-count then this count is re-used. If there is no preceding right-parenthesis then the whole format is re-used. Forced reversion has no effect upon the settings for scale-factor, sign, or blank control. Forced reversion can be useful when reading or writing an array contained on a sequence of records since it is not necessary to know how many records there are in total, but when producing printed output it is easy to forget that a carriage-control character is required for each record, even those produced by forced reversion.
List-directed output uses a format chosen by the system according to the data type of the item. The exact layout is system-dependent, but the general rules are as follows.
Each WRITE statement starts a new record; additional records are produced when necessary. Each record starts with a single blank to provide carriage-control on printing. Arithmetic data types are converted to decimal values with the number of digits appropriate for the internal precision; integer values will not have a decimal point, the system may choose fixed-point or exponential (scientific) form for floating-point values depending on their magnitude. Complex values are enclosed in parentheses with a comma separating the two parts.
Logical values are output as a single letter, either T or F. Character values are output without enclosing apostrophes; if a character string is too long for one record it may be continued on the next. Except for character values, each item is followed by at least one blank or a comma (or both) to separate it from the next value.
The rules for List-directed input effectively allow free-format entry for numerical data. Each READ statement starts with a new record and reads as many records as are necessary to satisfy its data-transfer list. The input records must contain a suitable sequence of values and separators.
The values may be given in any form which would be acceptable in a Fortran program for a constant of the corresponding type, except that embedded blanks are only permitted in character values. When reading a real or double-precision value an integer constant will be accepted; when reading a logical value only the letter T or F is required (a preceding dot and any following characters will be ignored). Note that a character constant must be enclosed in apostrophes and a complex constant must be enclosed in parentheses with a comma between the two components. If a character constant is too long to fit on one record it may be continued on to the next; the two parts of a complex constant may also be given on two records.
The separator between successive values must be one or more blanks, or a comma, or both. A new record may start at any point at which a blank would be permitted.
If several successive items are to have the same value a repetition factor can be used: this has the form n*constant where n is an unsigned integer. Blanks are not allowed either side of the asterisk.
Two successive commas represent a null value: the corresponding variable in the READ statement has its value unchanged. It is also possible to use the form n* to represent a set of n null values.
A slash (/) may be used instead of an item separator; it has the effect of completing the current READ without further input; all remaining items in its data transfer list are unchanged in value.
List-directed output files are generally compatible with list-directed input, unless they contain character items, which will not have the enclosing apostrophes which are required on input.
Although a format specification allows complete control over the layout of each line of text, it does not include any way of controlling pagination. The only way to do this is by using a unique and extraordinary mechanism dating back to the earliest days of Fortran. Even if you are not concerned with pagination you still need to know about the carriage-control convention since it is liable to affect every text file you produce.
Whenever formatted output is sent to a ``printer", the first character of every record is removed and used to control the vertical spacing. This carriage-control character must be one of the four listed in the the table below.
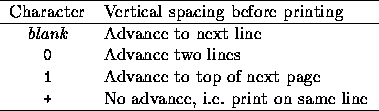
An empty record is treated as if it started with a single blank. For example, these statements start a new page with a page number at the top and a title on the third line:
WRITE(LP, 55) NUMBER, 'Report and Accounts'
55 FORMAT('1PAGE', I4, /, '0', A)
This carriage-control convention is an absurd relic which
causes a multitude of problems in practice. Firstly, systems differ
on what they call a ``printer": it may or may not apply to visual
display terminals or to text initially saved on a disc file and later
printed out. Some operating systems have a special file type for
Fortran formatted output which is treated differently by printers
(and terminals). Others have been known to chop off the first
character of all files sent to the system printer so that special
utilities are needed to print ordinary text.
To be on the safe side you should always provide an explicit carriage-control character at the start of each format specification and after each slash. Special care is needed in formats which use forced reversion. Normal single spacing is obtained with a blank, conveniently produced by the 1X edit descriptor. If you forget and accidentally print a number at the start of each record with a leading digit 1 then each record will start a new page.
The effect of + as a carriage-control character would be more useful if its effects were more predictable. Some devices over-print the previous record (allowing the formation of composite characters like ), others append to it, and some (including many visual display terminals) erase what was there before. In portable software there is no alternative but to ignore the + case altogether.
Standard Fortran can only use the four carriage-control characters listed in the table but many systems use other symbols for special formatting purposes, such as setting vertical spacing, changing fonts, and so on. One extension which is widely available is the use of the currency symbol $ to suppress carriage-return at the end of the line. This can be useful when producing terminal prompts as it allows the reply to be entered on the same line. There is, unfortunately, no way of doing this in Standard Fortran.
The rules for list-directed output ensure that the lines are single-spaced by requiring at least one blank at the start of every record.
The I/O statements fall into three groups:
All these statements have a similar general form (except that only
the READ and WRITE statements can have a data-transfer
list):
READ( control-list ) input-list
WRITE( control-list ) output-list
The items in each list are separated by commas. Those in the
control list are usually specified by keywords, in which case the
order does not matter, although it is conventional to have the unit
identifier first. For compatibility with Fortran66, if the unit
identifier does come first then the keyword UNIT= may be
omitted. Furthermore, when this keyword is omitted in READ and
WRITE statements and the format identifier is second its keyword
may also be omitted. Thus these two statements are exactly
equivalent:
READ(UNIT=1, FMT=*, ERR=999) AMPS, VOLTS, HERTZ
READ(1, *, ERR=999) AMPS, VOLTS, HERTZ
Use of this abbreviated form is a matter of taste: for the sake of
clarity the keywords will all be shown in other examples.
Many of the keywords in the control-list can take a character expression as an argument: in such cases any trailing blanks in the value will be ignored. This makes it easy to use character variables to specify file names and characteristics.
There is one general restriction on expressions used in all I/O statements: they must not call external functions which themselves execute further I/O statements. This restriction avoids the possibility of recursive calls to the I/O system.
The OPEN statement is used to connect a file to an I/O unit and describe its characteristics. It can open an existing file or create a new one. If the unit is already connected to another file then this is closed before the new connection is made, so that it is impossible to connect two files simultaneously to the same unit. It is an error to try to connect more than one unit simultaneously to the same file. In the special case in which the unit and file are already connected to each other, the OPEN statement may be used to alter the properties of the connection, although in practice only the BLANK= (and sometimes RECL=) values can be changed in this way.
The Fortran Standard does not specify the file position when an existing sequential file is opened. Although most operating systems behave sensibly, in portable software a REWIND statement should be used to ensure that the file is rewound before you read it.
The general form of the OPEN statement is just:
OPEN( control-list )
The control-list can contain any of the following items in any
order:

The default value is 'UNKNOWN', but it is unwise to omit the STATUS keyword because the effect of 'UNKNOWN' is so ill-defined.
![]()
![]()
![]()
The default value is likely to be the sensible choice in all cases.
The CLOSE statement is used to close a file and break its
connection to a unit. The unit and the file (if it still exists) are then
free for re-use in any way. If the specified unit is not connected to
a file the statement has no effect. The general form of the
statement is:
CLOSE( control-list )
where the control-list may contain the following items:
The INQUIRE statement can be used in two slightly different
forms:
INQUIRE(UNIT= integer-expression, inquire-list
)
INQUIRE(FILE= em character-expression, inquire-list
)
The first form, an inquire by unit, returns information about the
unit and, if it is connected to a file, about the file as well. If it is
not connected to a file then most of the arguments will be
undefined or return a value of 'UNKNOWN' as appropriate.
The second form, inquire by file, can always be used to find out whether a named file exists, i.e. can be opened by a Fortran program. Any trailing blanks in the character expression are ignored, and the forms of file-name acceptable are, as in the OPEN statement, system-dependent. If the file exists and is connected to a unit then much more information can be obtained.
The inquire-list may contain any of the items below. Note that all of them (except for ERR=label) return information by assigning a value to a named variable (or array element). The normal rules of assignment statements apply, so that so that character items may have any reasonable length will return a value which is padded out with blanks to its declared length if necessary.
The READ statement reads information from one or more records on a file into a list of variables, array elements, etc. The WRITE statement writes information from a list of items which may include variables, arrays, and expressions and produces one or more records on a file. Each READ or WRITE statement can only transfer one record on an unformatted file but on formatted files, including internal files, more than one record may be transferred, depending on the contents of the format specification.
The two statements have the same general form:
READ( control-list ) data-list
WRITE( control-list ) data-list
The control-list must contain a unit identifier; the other items may
be optional depending on the type of file. The data-list is also
optional: if it is absent the statement transfers one record (or
possibly more under the control of a format specification).
This may have any of the following forms:
Note that the keyword UNIT= is optional if the unit identifier is the first item in the control list.
A format identifier must be provided when using a formatted (or internal) file but not otherwise. It may have any of the following forms:
A record number identifier must be provided for direct-access files but not otherwise. It has the form:
REC=integer-expression
The record number must be greater than zero; for READ it must refer to a record which exists.
These may be provided in any combination, but END=label is only valid when reading a sequential or internal file. See 10.5 for more information.
END=label ERR=label IOSTAT=integer-variable
The data list of a READ statement may contain variables, array-elements, character-substrings, or complete arrays of any data type. An array-name without subscripts represents all the elements of the array; this is not permitted for assumed-size dummy arguments in procedures (because the array size is indeterminate). The list may also contain implied DO-loops (explained below).
The data list of a WRITE statement may contain any of the items permitted in a READ statement and in addition expressions of any data type. As in all I/O statements, expressions must not themselves involve the execution of other I/O statements.
The simplest and most efficient way to read or write all the elements of an array is to put its name, unsubscripted, in the data-transfer list. In the case of a multi-dimensional array the elements will be transferred in the normal storage sequence, with the first subscript varying most rapidly.
An implied-DO loop allows the elements to be transferred selectively or in some non-standard order. The rules for an implied-DO are similar to that of an ordinary DO-loop but the loop forms a single item in the data-transfer list and is enclosed by a pair of parentheses rather than by DO and CONTINUE statements. For example:
READ(UNIT=*, FMT=*) (ARRAY(I), I= IMIN, IMAX)
WRITE(UNIT=*, FMT=15) (M, X(M), Y(M), M=1,101,5)
15 FORMAT(1X, I6, 2F12.3)
A multi-dimensional array can be printed out in a transposed form. The next example outputs an array X(100,5) but with 5 elements across and 100 lines vertically:
WRITE(UNIT=*, FMT=5) (I,I=1,5),
$ ((L,X(L,I),I=1,5),L=1,100)
5 FORMAT(1X,'LINE', 5I10, 100(/,1X,I4, 5F10.2))
The first loop writes headings for the five columns, then the double loop writes a line-number for each line followed by five array elements. Note that the parentheses have to be matched and that a comma is needed after the inner right-parenthesis since the inner loop is just an item in the list contained in the outer loop.
The implied DO-loop has the general form:
( data-list, loop-variable = start,
limit, step )
where the rules for the start, limit, and step values
are exactly as in an ordinary DO statement. The
loop-variable (normally an integer) may be used within the data-list and
this list may, in turn, include further complete implied-DO lists.
If an error or end-of-file condition occurs in an implied DO-loop then the loop-control variable will be undefined on exit; this means that an explicit DO-loop is required to read an indefinite list of data records and exit with knowledge of how many items were actually input.
These file-positioning statements may only be used on external sequential files; most systems will restrict them to files stored on suitable peripheral devices such as discs or tapes.
REWIND repositions a file to the beginning of information so that the next READ statement will read the first record; if a WRITE statement is used after REWIND all existing records on the file are destroyed. REWIND has no effect if the file is already rewound. If a REWIND statement is used on a unit which is connected but does not exist (e.g. a pre-connected output file) it creates the file.
BACKSPACE moves the file position back by one record so that the record can be re-read or over-written. There is no effect if the file is already positioned at the beginning of information but it is an error to back-space a file which does not exist. It is also illegal to back-space over records written by list-directed formatting (because the number of records produced each time is system-dependent). A few operating systems find it difficult to implement the BACKSPACE statement directly and actually manage it only by rewinding the file and spacing forward to the appropriate record. It is sometimes possible to avoid backspacing a file by allocating buffers within the program and, for a formatted file, using an internal file READ and WRITE statements.
These statements have similar general forms:
REWIND( control-list )
BACKSPACE( control-list )
where the control-list may contain:
UNIT=integer-expression
IOSTAT=integer-variable
ERR=label
The unit identifier is compulsory, the others optional. If only the
unit identifier is used then (for compatibility with Fortran66) an
abbreviated form of the statement is permitted: REWIND integer-expression BACKSPACE integer-expression